Les attaques par phishing utilisant les noms de domaine internationalisés ont récemment eu le vent en poupe grâce à la découverte du chercheur Xudong Zhenga montrant que les navigateurs échouaient à montrer la différence entre deux noms de domaine composés d’alphabets différents. Nous avons voulu pousser l’expérience un peu plus loin en ne se limitant pas seulement à l’alphabet Cyrillique mais en utilisant l’alphabet latin qui offre beaucoup plus de possibilités dans la création d’un nom de domaine.
Mais avant de rentrer dans le vif du sujet, un petit rappel sur Unicode s’impose.
QU’EST-CE QUE L’UNICODE ?
L’Unicode est un standard mondial d’encodage de caractère. Il permet des échanges de textes dans différentes langues à un niveau mondial, en attribuant à chaque caractère un identifiant unique et ce quel que soit l’alphabet.
“ Unicode provides a unique number for every character, no matter what the platform, no matter what the program, no matter what the language.”
http://unicode.org/standard/WhatIsUnicode.html
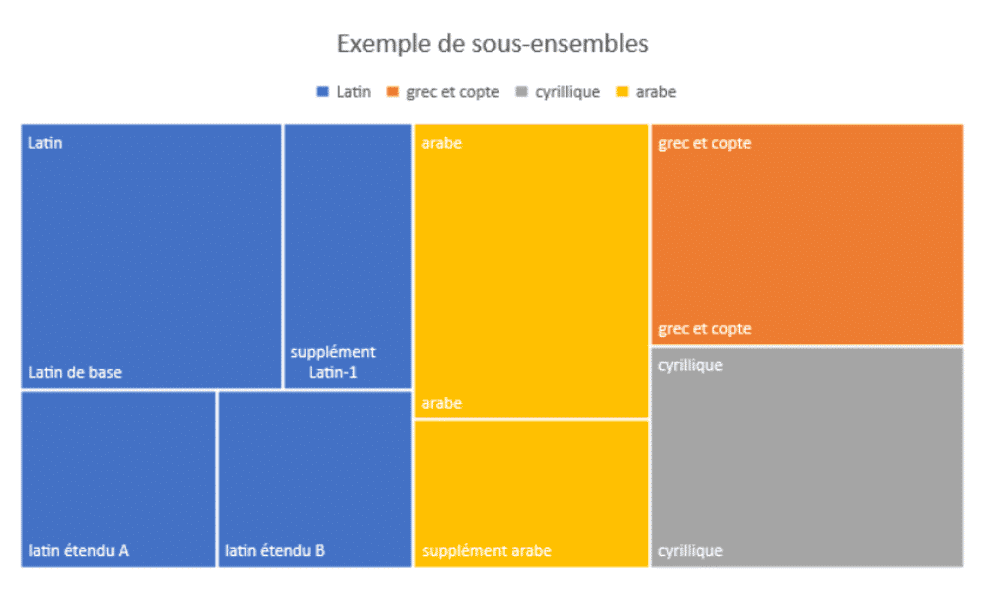
Il existe au total, 34 sous-ensembles de caractères Unicode où chaque sous-ensemble représente un alphabet particulier propre à une langue ou une région (Grec, Copte, Russe etc).Il est intéressant de noter que l’alphabet Latin est lui-même composé de plusieurs « suppléments » (latin étendu etc). Ceci élargit le champ des possibilités d’un attaquant, comme nous le verrons après.
Les navigateurs modernes prennent en charge l’affichage de l’Unicode et ce y compris dans l’affichage de l’URL. Exemple avec ce lien qui redirige vers le Wikipédia Coréen :
https://ko.wikipedia.org/wiki/위키백과:대
L’affichage des URL au format Unicode par les navigateurs a été implémenté pour apporter « une meilleure expérience utilisateur ».
“This is a challenging problem space. Chrome has a global user base of billions of people around the world[..] ensuring that users across languages have a great experience in Chrome.”
https://www.chromium.org/developers/design-documents/idn-in-google-chrome
QU’EST-CE QUE LE PUNYCODE ?
Le Punycode est une façon de représenter les IDN, c’est-à-dire les noms de domaine qui ont des caractères n’utilisant pas l’alphabet latin de base. Les seuls caractères autorisés en Punycode sont dans les ensembles [a-z] et [0-9].
Par exemple, le nom de domaine facẹḅook.com, pour lequel le « e » et le « b » ont été remplacés par des caractères d’un alphabet non latin, donne en Punycode : xn--facook-rg7bx3d.com
Il faut remarquer que l’encodage Punycode est facilement repérable car il commence par xn-- ; cet encodage est normalement affiché dans l’URL du navigateur lorsqu’une personne souhaite se rendre sur le site.Cela permet notamment d’éviter les attaques homographiques, qui exploitent l’affichage et l’interprétation du nom de domaine par le navigateur.
Les attaques homographiques sont grandement documentées sur Internet. The Chromium Project en a fait un article, expliquant pourquoi le navigateur devait afficher les URL comprenant des caractères non latins en Punycode.
“In a perfect world, domain registrars would not allow these confusable domain names to be registered. Some TLD registrars do exactly that, mostly by restricting the characters allowed, but many do not. As a result, all browsers try to protect against homograph attacks by displaying punycode (looks like « xn-- … ») instead of the original IDN, according to an IDN policy.”
https://www.chromium.org/developers/design-documents/idn-in-google-chrome
Or, il se trouve que certains navigateurs dont Chromium et Firefox n’affichent pas toutes les URL en Punycode mais directement en Unicode pour, une fois de plus, « améliorer l’expérience utilisateur ». Nous avons notamment découvert que les caractères qui sont des suppléments de l’alphabet latin (Latin -> Supplément Latin-1) sont affichés en Unicode par défaut. Nous avons par exemple testé de réaliser une attaque homographique avec le nom de domaine http://xn--facook-rg7bx3d.com, qui sera affiché http://facẹḅook.com dans le navigateur, mélangeant les sous-ensembles « Latin de base » et « Supplément Latin-1 .
Cela signifie pour un attaquant qu’il est beaucoup plus facile de mener des campagnes de phishing puisqu’il peut maintenant acheter un nom de domaine Unicode qui se rapproche visuellement le plus possible du nom de domaine ciblé.Pour mener une attaque par phishing réaliste et efficace, l’attaquant peut donc utiliser le nom de domaine Unicode précédemment acheté pour envoyer des mails en se faisant passer pour Facebook. Le client de messagerie et le navigateur n’afficheront ni l’un ni l’autre le nom de domaine en Punycode.
SE PRÉMUNIR DE CE TYPE D’ATTAQUE :
Quelques règles simples peuvent être suivies pour se prémunir contre les attaques homographiques :
- Le premier réflexe est de ne jamais ouvrir les liens et les pièces jointes contenus dans les mails.
- Pour détecter efficacement si le domaine est en Unicode, il suffit de copier/coller l’URL dans le bloc note, pour voir apparaître le nom de domaine encodé en Punycode.
- Une autre technique, si le site web utilise un certificat HTTPS, est d’afficher les propriétés du certificat
LES LIMITATIONS DES ATTAQUES HOMOGRAPHIQUES
Bien que les possibilités soient larges ne utilisant l’alphabet latin et ses suppléments, les attaque homographiques sont toutefois limitées en pratique par les restrictions suivantes :
- Seuls les domaines .biz, .com, .info, .museum, .net et .org acceptent des libellés de nom de domaine non ASCII. Les autres domaines ont des libellés très restreints voire inexistants. Exemple avec les .fr, pour lesquels la liste des caractères non ASCII acceptés est : ß à á â ã ä å æ ç è é ê ë ì í î ï ñ ò ó ô õ ö ù ú û ü ý ÿ œ (https://fr.wikipedia.org/wiki/Nom_de_domaine_internationalis%C3%A9)
- La gestion des mails pour un domaine contenant des caractères Unicode non latins est fastidieuse. Par exemple, le client mail Thunderbird affiche l’e-mail au format Punycode et non Unicode. Le service mail Gmail refuse tout simplement les domaines en Unicode.
- Les règles fixées par l’ICANN (Internet Corporation for Assigned Names and Numbers), ne permettent pas d’utiliser différents alphabets pour un même nom de domaine :
“In such cases, visually confusable characters from different scripts will not be allowed to co-exist in a single set of permissible codepoints unless a corresponding policy and character table is clearly defined.”
https://www.icann.org/resources/unthemed-pages/idn-guidelines-2005-11-14-en
En conséquence, le fournisseur de noms de domaine testé pour notre attaque n’a pas permis d’acheter le nom de domaine de notre choix, comme le montre l’image suivante avec le domaine facebook.com en utilisant deux caractères Omicron à la place des deux « o » latin :
- Même si un fournisseur de domaine autorise les noms de domaine Unicode, les navigateurs modernes ont mis en place des limitations dans l’affichage des IDN. Par exemple, pour Firefox et Chromium, l’algorithme suivant (simplifié) est appliqué :
1. Si le composant utilises des caractères tirés d’alphabets différents, il est sujet à une vérification basée sur le profil « modérément restrictif » de l’UTS 39 avec une règle additionnelle pour l’alphabet Latin. Si la vérification échoue, le composant est affiché en Punycode.
- Les caractères Latin, Cyrillique ou Grec ne peuvent être mélangés
- Les caractères Latin dans la plage ASCII peuvent être mélangés avec d’autres alphabets tant que ces derniers ne sont ni Grecs ni Cyrilliques.
- Les caractères Han (Ideogrammes Chinois, Japonnais et Coréens) peuvent être mélangés avec les caractères Bopomofo.
- Les caractères Han peuvent être mélangés avec les Hiragana et Katakana.
- Les caractères Han peuvent être mélangés avec l’Hangul coréen.
2. Si le nom de domaine appartient à un TLD non IDN, comme .com, .net ou .uk, et que toutes les lettres appartiennent à un ensemble de caractères cyrilliques qui ressemblent à des lettres latines, alors afficher le composant en Punycode.
3. Si le nom correspond à un pattern reconnu comme dangereux, alors afficher en Punycode.
4. Sinon, afficher en Unicode.
Source : https://www.chromium.org/developers/design-documents/idn-in-google-chrome
Note : Récemment le chercheur Xudong Zhenga a publié un article détaillant comment contourner le problème de l’affichage en Punycode en utilisant un nom de domaine dans un seul alphabet (Cyrillique). Il a ainsi démontré une vulnérabilité dans l’algorithme utilisé pour éviter les attaques homographiques en achetant le domaine www.аррӏе.com . Cette vulnérabilité sera corrigée fin Avril 2017 par les différents navigateurs. L’attaque reste tout de même limitée car le Cyrillique ne possède pas tout l’alphabet latin. Il est difficile de dire comment la correction de cette vulnérabilité impactera l’affichage des domaines Unicode composés de caractères suppléments d’un alphabet comme montré avec l’exemple de facẹḅook.com
- Selon la version du navigateur et le système d’exploitation utilisés, l’affichage est plus ou moins détectable, comme en atteste ces captures d’écrans réalisées respectivement sous Linux, Windows et Mac OS en utilisant le nom de domaine Unicode : https://www.xn--facook-rg7bx3d.com/